The best way to use massive language fashions and data graphs to handle enterprise information
[ad_1]
Be part of prime executives in San Francisco on July 11-12, to listen to how leaders are integrating and optimizing AI investments for achievement. Be taught Extra
Lately, data graphs have turn into an necessary software for organizing and accessing massive volumes of enterprise information in numerous industries — from healthcare to industrial, to banking and insurance coverage, to retail and extra.
A data graph is a graph-based database that represents data in a structured and semantically wealthy format. This might be generated by extracting entities and relationships from structured or unstructured information, resembling textual content from paperwork. A key requirement for sustaining information high quality in a data graph is to base it on normal ontology. Having a standardized ontology typically entails the price of incorporating this ontology within the software program growth cycle.
Organizations can take a scientific method to producing a data graph by first ingesting a typical ontology (like insurance coverage danger) and utilizing a massive language mannequin (LLM) like GPT-3 to create a script to generate and populate a graph database.
The second step is to make use of an LLM as an intermediate layer to take pure language textual content inputs and create queries on the graph to return data. The creation and search queries could be personalized to the platform wherein the graph is saved — resembling Neo4j, AWS Neptune or Azure Cosmos DB.
Occasion
Remodel 2023
Be part of us in San Francisco on July 11-12, the place prime executives will share how they’ve built-in and optimized AI investments for achievement and prevented frequent pitfalls.
Combining ontology and pure language strategies
The method outlined right here combines ontology-driven and pure language-driven strategies to construct a data graph that may be simply queried and up to date with out in depth engineering efforts to construct bespoke software program. Under we offer an instance of an insurance coverage firm, however the method is common.
The insurance coverage trade is confronted with many challenges, together with the necessity to handle massive quantities of knowledge in a manner that’s each environment friendly and efficient. Data graphs present a method to arrange and entry this information in a structured and semantically wealthy format. This will embrace nodes, edges and properties the place nodes characterize entities, edges characterize relationships between entities and properties characterize at-tributes of entities and relationships.
There are a number of advantages to utilizing a data graph within the insurance coverage trade. First, it gives a method to arrange and entry information that’s straightforward to question and replace. Second, it gives a method to characterize data in a structured and semantically wealthy format, which makes it simpler to investigate and interpret. Lastly, it gives a method to combine information from completely different sources, together with structured and unstructured information.
Under is a 4 step method. Let’s assessment every step intimately.
Method
Step 1: Finding out the ontology and figuring out entities and relations
Step one in producing a data graph is to review the related ontology and establish the entities and relationships which might be related to the area. An ontology is a proper illustration of the data in a website, together with the ideas, relations and constraints that outline the area. Insurance coverage danger ontology defines the ideas and relationships which might be related to the insurance coverage area, resembling coverage, danger and premium.
The ontology could be studied utilizing numerous strategies together with handbook inspection and automatic strategies. Guide inspection entails studying the ontology documentation and figuring out the related entities and relationships. Automated strategies use pure language processing (NLP) strategies to extract the entities and relationships from the ontology documentation.
As soon as the related entities and relationships have been recognized, they are often organized right into a schema for the data graph. The schema defines the construction of the graph, together with the varieties of nodes and edges that will probably be used to characterize the entities and relationships.
Step 2: Constructing a textual content immediate for LLM to generate schema and database for ontology
The second step in producing a data graph entails constructing a textual content immediate for LLM to generate a schema and database for the ontology. The textual content immediate is a pure language description of the ontology and the specified schema and database construction. It serves as enter to the LLM, which generates the Cypher question for creating and populating the graph database.
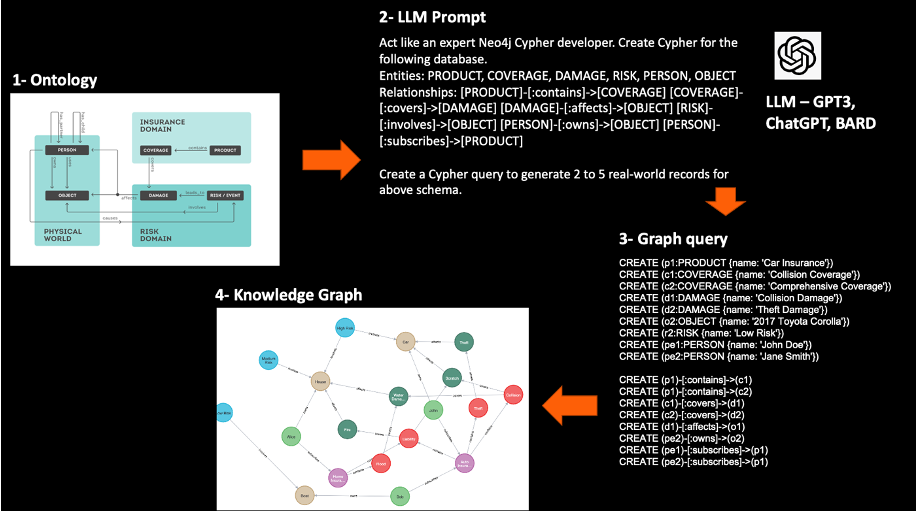
The textual content immediate ought to embrace an outline of the ontology, the entities and relationships that had been recognized in step 1, and the specified schema and database construction. The outline must be in pure language and must be straightforward for the LLM to grasp. The textual content immediate also needs to embrace any constraints or necessities for the schema and database, resembling information varieties, distinctive keys and international keys.
For instance, a textual content immediate for the insurance coverage danger ontology would possibly appear like this:
“Create a graph database for the insurance coverage danger ontology. Every coverage ought to have a novel ID and must be related to a number of dangers. Every danger ought to have a novel ID and must be related to a number of premiums. Every premium ought to have a novel ID and must be related to a number of insurance policies and dangers. The database also needs to embrace constraints to make sure information integrity, resembling distinctive keys and international keys.”
As soon as the textual content immediate is prepared, it may be used as enter to the LLM to generate the Cypher question for creating and populating the graph database.
Step 3: Creating the question to generate information
The third step in producing a data graph entails creating the Cypher question to generate information for the graph database. The question is generated utilizing the textual content immediate that was created in step 2 and is used to create and populate the graph database with related information.
The Cypher question is a declarative language that’s used to create and question graph databases. It consists of instructions to create nodes, edges, and relationships between them, in addition to instructions to question the information within the graph.
The textual content immediate created in step 2 serves as enter to the LLM, which generates the Cypher question primarily based on the specified schema and database construction. The LLM makes use of NLP strategies to grasp the textual content immediate and generate the question.
The question ought to embrace instructions to create nodes for every entity within the ontology and edges to characterize the relationships between them. For instance, within the insurance coverage danger ontology, the question would possibly embrace instructions to create nodes for insurance policies, dangers and premiums, and edges to characterize the relationships between them.
The question also needs to embrace constraints to make sure information integrity, resembling distinctive keys and international keys. This can assist to make sure that the information within the graph is constant and correct.
As soon as the question is generated, it may be executed to create and populate the graph database with related information.
Ingesting the question and making a data graph
The ultimate step in producing a data graph entails ingesting the Cypher question and making a graph database. The question is generated utilizing the textual content immediate created in step 2 and executed to create and populate the graph database with related information.
The database can then be used to question the information and extract data. The graph database is created utilizing a graph database administration system (DBMS) like Neo4j. The Cypher question generated in step 3 is ingested into the DBMS, which creates the nodes and edges within the graph database.
As soon as the database is created, it may be queried utilizing Cypher instructions to extract data. The LLM will also be used as an intermediate layer to take pure language textual content inputs and create Cypher queries on the graph to return data. For instance, a person would possibly enter a query like “Which insurance policies have a high-risk ranking?” and the LLM can generate a Cypher question to extract the related information from the graph.
The data graph will also be up to date as new information turns into accessible. The Cypher question could be modified to incorporate new nodes and edges, and the up to date question could be ingested into the graph database so as to add the brand new information.
Benefits of this method
Standardization
Ingesting a typical ontology like insurance coverage danger ontology gives a framework for standardizing the illustration of information within the graph. This makes it simpler to combine information from completely different sources and ensures that the graph is semantically constant. By utilizing a typical ontology, the group can be sure that the information within the data graph is constant and standardized. This makes it simpler to combine information from a number of sources and ensures that the information is comparable and significant.
Effectivity
Utilizing GPT-3 to generate Cypher queries for creating and populating the graph database is an environment friendly method to automate the method. This reduces the time and assets required to construct the graph and ensures that the queries are syntactically and semantically right.
Intuitive querying
Utilizing LLM as an intermediate layer to take pure language textual content inputs and create Cypher queries on the graph to return data makes querying the graph extra intuitive and user-friendly. This reduces the necessity for customers to have a deep understanding of the graph construction and question language.
Productiveness
Historically, creating a data graph concerned customized software program growth, which could be time-consuming and costly. With this method, organizations can leverage current ontologies and NLP instruments to generate the question, lowering the necessity for customized software program growth.
One other benefit of this method is the power to replace the data graph as new information turns into accessible. The Cypher question could be modified to incorporate new nodes and edges, and the up to date question could be ingested into the graph database so as to add the brand new information. This makes it simpler to keep up the data graph and be sure that it stays up-to-date and related.
Dattaraj Rao is chief information scientist at Persistent.
DataDecisionMakers
Welcome to the VentureBeat neighborhood!
DataDecisionMakers is the place specialists, together with the technical individuals doing information work, can share data-related insights and innovation.
If you wish to examine cutting-edge concepts and up-to-date info, finest practices, and the way forward for information and information tech, be part of us at DataDecisionMakers.
You would possibly even think about contributing an article of your personal!
[ad_2]
No Comment! Be the first one.